Asking a computer system to generate random data can be a difficult task. By design, computer processors execute a set of given commands in a certain sequence. When given the same set of input conditions (e.g. time of day, the contents of a file on disc, input from a user), running a program should produce exactly the same output every time it is run. This presents a difficulty when we want to build in some unpredictability into the output, such as when we deal with gambling, modelling or gaming applications.
What is random data?
It is important to define exactly what we mean by “random” data. Mathematically, we can define a “truly random” variable \(X\) as follows.
Define \(X_k\) as the value of \(X\), for \(k=1,2,3,…\). Assume \(X_k=0\) or \(X_k=1\) for all \(k\). We can also define \(\mathbb{P}\left({X_k=x}\right)\) as the probability that \(X_k\) takes the value of \(x\) — this will be between 0 (impossible) and 1 (certain).
We say that \(X\) is truly random if \(\mathbb{P}\left({X_n=x}\right)\leq 0.5\) for all \(x\), despite having knowledge of the value of \(X_k\) for all \(k\leq n\). In other words, we cannot accurately predict the outcome of the \(n\)th event, despite knowing the outcome of all the events \(X_k\) that came before.
As an example of a truly random variable, take \(X_k\) as the result of the \(k\)th toss of a fair coin (we can encode 0 as “heads” and 1 as “tails” in this example). Then, after 1,000 tosses of the coin, we are no closer to predicting the result of toss number 1,001 than we were at the start. This means that \(X\) is truly random.
How do we measure randomness?
It’s all well and good if we can prove the randomness of data from exact mathematical models. Unfortunately, variables in the real world are rarely so well-behaved. We therefore use statistical methods to measure the quality of randomness. Where data is not truly random (e.g. when data is generated by an algorithm and is “random enough” for its intended purpose) we can assign a value of randomness to the data set, thereby giving us an idea of the degree of randomness of the data. We say that this data is “pseudo-random”.
A popular tool to test for randomness, and one which I will be using in a future article, is the Diehard test suite. It employs various statistical techniques to measure the randomness of a data set, and by all accounts it is considered an accurate method to compare the randomness of data sets against each other.
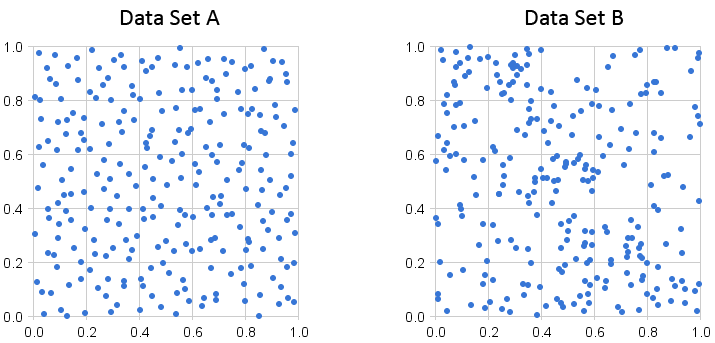
A common logical fallacy is that Data Set A is more random, due to the data points being spread quite evenly. This is in contrast to Data Set B which has formed clusters around certain points. However, Data Set B is the more random set of data — each new data point is plotted independently of all other points that were collected before it, so some unevenness in the distribution can (and should, to some extent) be expected. (This is another way of saying that a random variable distributed uniformly over a range cannot be considered truly random.)
How do computers produce random data?
Returning to the problem of computers producing unpredictable results, it is clear that there needs to be some sort of outside influence to provide the randomness — otherwise we meet difficulties as mentioned in the introduction. We get around this problem by reading in data from the surrounding “real” environment with sufficiently high precision. For example:
- Measuring radioactive decay (these are quantum events and so are truly random — but unlikely to be found inside a consumer device!).
- Measuring electrical and mechanical noise in chaotic physical systems (truly random).
- The highest-precision timings of keyboard button presses, mouse movements and IDE timings (not truly random, but pseudo-random). These are the main sources of randomness used in the Linux kernel’s random number generator.
By reading data with a sufficiently high entropy from its environment, the computer can use this data (truly random or not) to seed its random number generator. A cryptographic algorithm uses this high-quality random data to output more pseudo-random data, which can and is then be used by other applications requiring a source of random data.
In the second part of this article, I will be looking at the different random number generation techniques available on a standard Linux system, comparing them for both performance and quality of randomness.